Abstract
Large language models have shown their remarkable capabilities as a general interface for various language-related applications. Motivated by this, we target to build a unified interface for completing many vision-language tasks including image description, visual question answering, and visual grounding, among others. The challenge for achieving this is to use a single model for performing diverse vision-language tasks effectively with simple multi-modal instructions. To address this issue, we introduce MiniGPT-v2, a model can be treated a unified interface for better handling various vision-language tasks. We propose using unique identifiers for different tasks when training the model. These identifiers enable our model to distinguish each task instruction effortlessly and also improve the model learning efficiency for each task. After our three-stage training, the experimental results show that MiniGPT-v2 achieves strong performance on many visual question answering and visual grounding benchmarks compared to other vision-language generalist models.
Model
MiniGPT-v2 consists of three components: a visual backbone, a linear projection layer, and a large language model.:
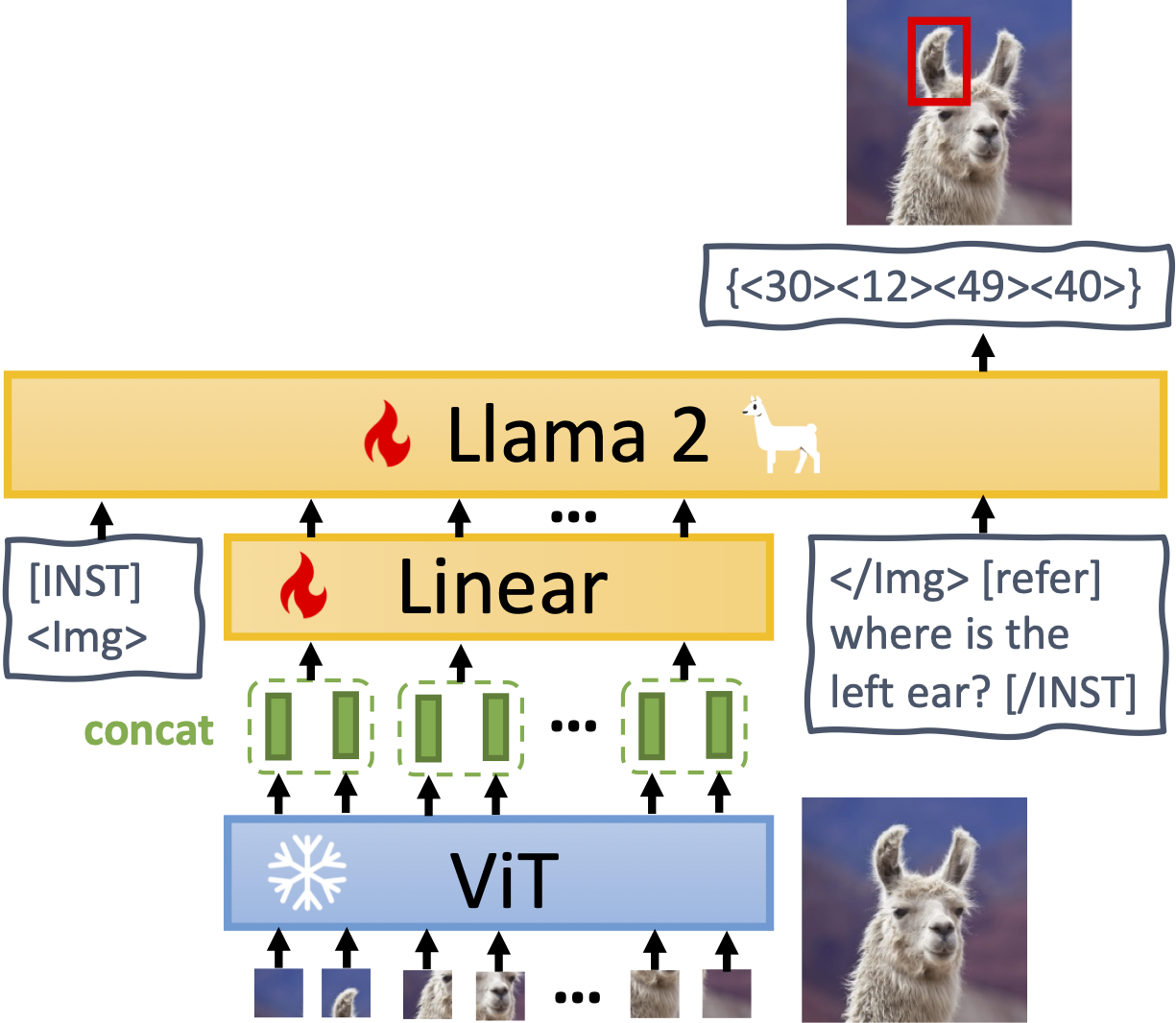
The architecture of MiniGPT-v2.
